

Introduction
The integration of artificial intelligence (AI) into healthcare has gained momentum, particularly with the advent of large language models (LLMs) such as ChatGPT. These AI systems have shown potential in various applications, including patient education and the interpretation of medical information. A recent study published in Clinical Chemistry titled “ChatGPT vs. Medical Professional: Analyzing Responses to Laboratory Medicine Questions on Social Media” investigates the effectiveness of ChatGPT compared to medical professionals in addressing patient queries related to laboratory medicine. This study is particularly relevant as more patients seek to understand their lab results through online platforms, where they might encounter AI-generated responses.
Study Findings
This was a comparative, observational study designed to evaluate the quality of responses provided by ChatGPT versions 3.5 and 4.0 versus those from medical professionals. The study analyzed 49 patient questions related to laboratory medicine, sourced from social media platforms Reddit and Quora, where licensed medical professionals had already provided answers. These same questions were then posed to ChatGPT. Responses were meticulously evaluated by licensed laboratory medicine professionals based on criteria such as quality, accuracy, and overall preference.
The findings were compelling: ChatGPT’s responses were preferred by 75.9% of evaluators, primarily for their comprehensiveness and accuracy. In contrast, while medical professionals’ responses were concise and direct, they often lacked the depth and detail that ChatGPT provided. Detailed analysis showed that the average length of responses from ChatGPT version 4.0 was 293 words, significantly longer than the 127-word average from medical professionals. Additionally, the study observed a fair level of interrater agreement, with a Fleiss kappa value of 0.217, indicating some subjectivity in evaluation but consistent preferences for ChatGPT’s detailed responses.
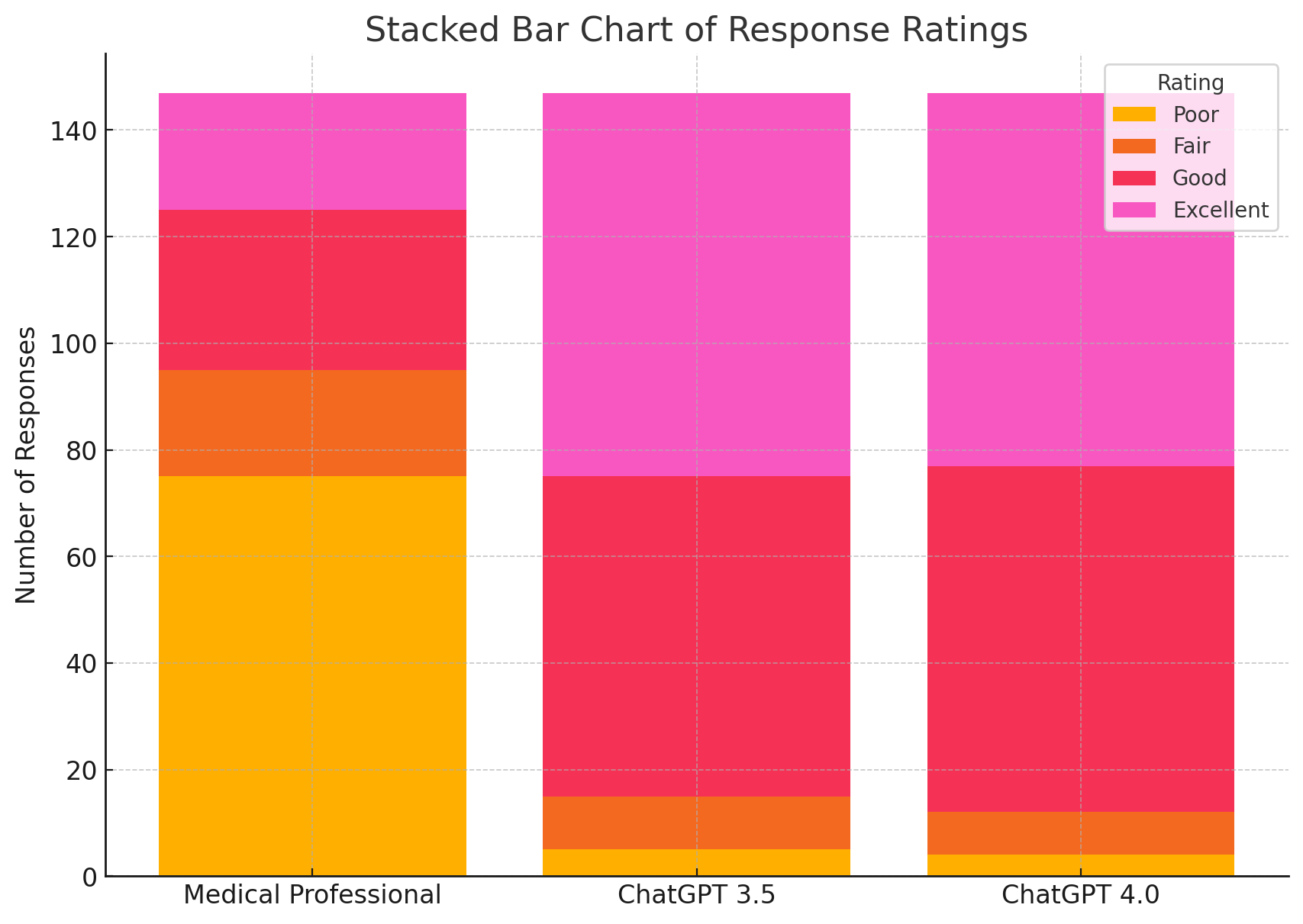
Preference for ChatGPT’s Responses (75.9%):
- Evaluators preferred ChatGPT’s responses in 75.9% of cases, largely due to the comprehensiveness and accuracy of the information provided. This suggests that ChatGPT can effectively convey detailed medical information that meets patient needs better than human professionals in some contexts.
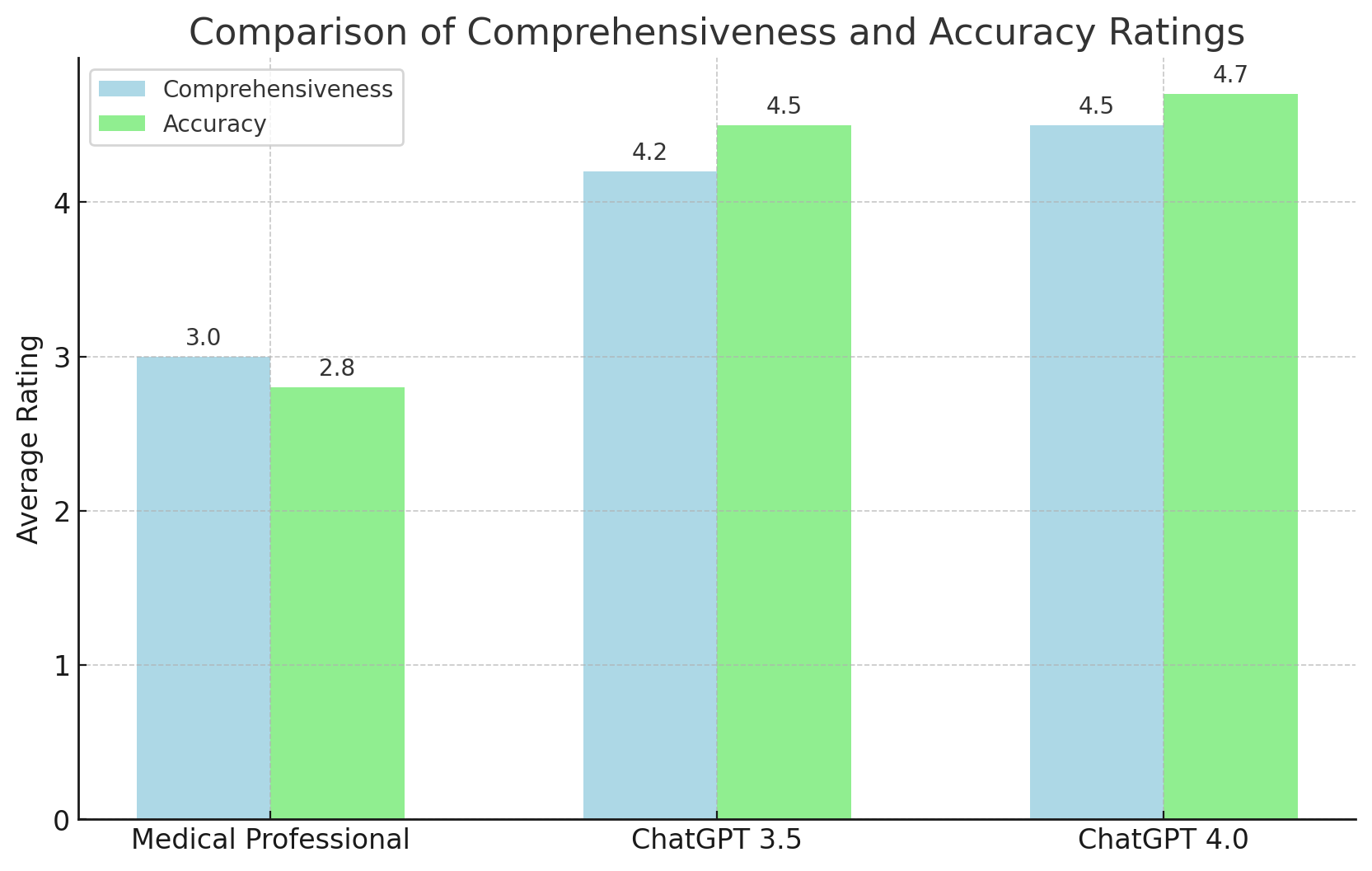
Comprehensiveness and Accuracy:
- ChatGPT’s responses were rated higher for being thorough and precise. This implies that the AI can synthesize complex medical information into a format that is both understandable and informative for patients, which is essential for addressing intricate medical queries.
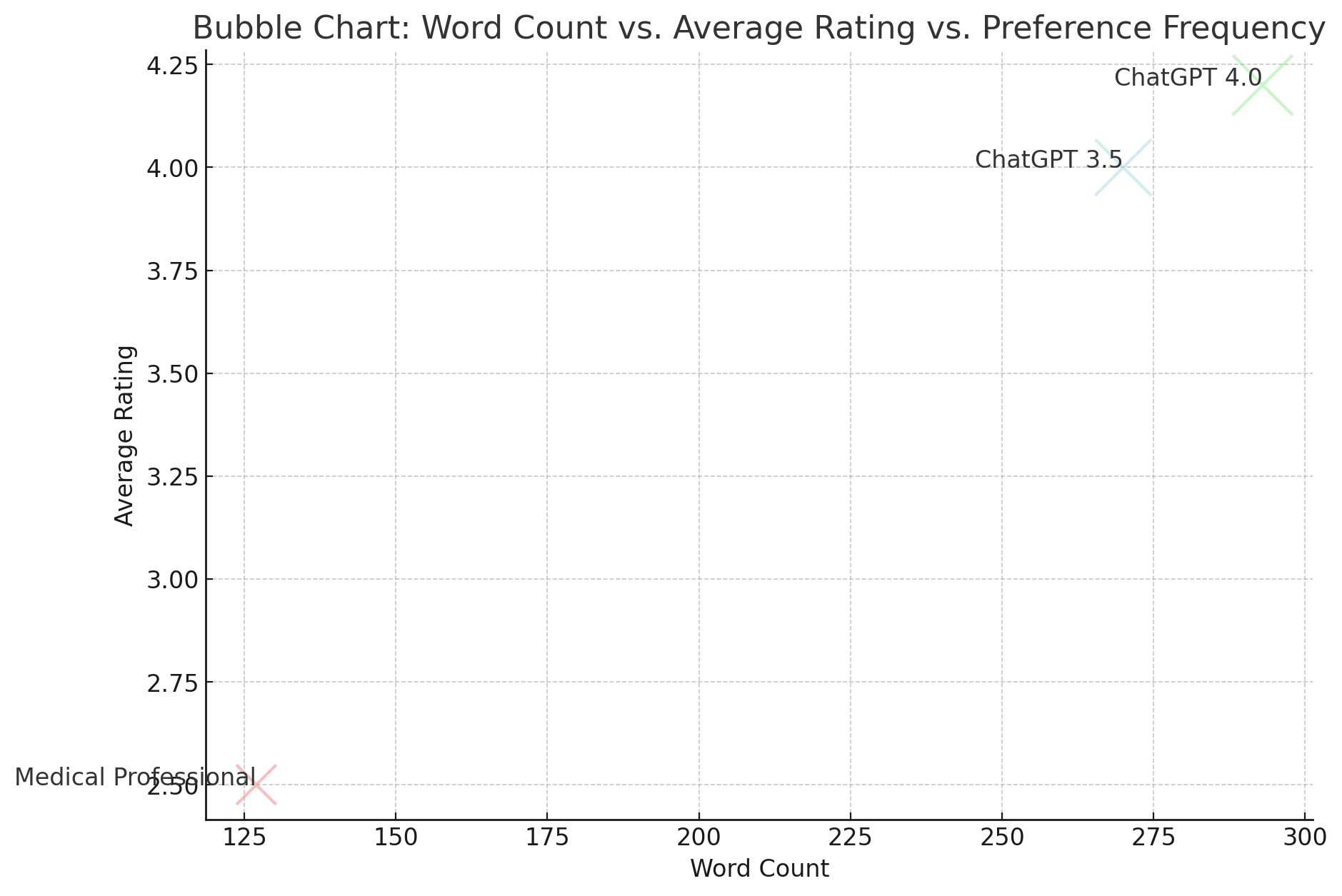
Length of Responses:
- The study found that ChatGPT version 4.0’s responses averaged 293 words, compared to 127 words from medical professionals. The longer responses indicate that ChatGPT provides more detailed explanations, which could help patients better understand their health conditions and test results. However, they also highlight the risk of information overload.
Conciseness of Professional Responses:
- While medical professionals’ responses were concise, they often lacked the depth seen in ChatGPT’s responses. This suggests that while brevity is valuable, especially in clinical settings, it may sometimes come at the cost of missing critical details that patients might find useful.
Interrater Agreement:
- The study’s Fleiss kappa value of 0.217 indicates a fair level of agreement among evaluators, showing that while there was some subjectivity in how responses were rated, the preference for ChatGPT was consistently observed. This suggests that, despite different evaluators, the trend of favoring AI-generated responses was clear.
Discussion
The study’s findings underscore the potential of ChatGPT as a valuable tool in patient education and engagement within the realm of laboratory medicine. The preference for ChatGPT’s responses suggests that patients value detailed and comprehensive explanations, which are essential when interpreting complex medical information. For instance, when addressing elevated potassium levels or the implications of abnormal thyroid function tests, ChatGPT’s ability to provide thorough, well-rounded explanations may enhance patient understanding and satisfaction.
However, the study also highlights the limitations of AI-generated responses. While ChatGPT excels in providing detailed information, there is a risk of overwhelming patients with too much data, which might obscure key takeaways or lead to confusion. Furthermore, AI cannot offer personalized medical advice that takes into account the patient’s complete medical history—a crucial aspect of care that only human professionals can provide. This underscores the importance of using AI as a complementary tool rather than a replacement for professional medical judgment.
Another key discussion point is the consistency of ChatGPT’s performance across different versions. The study found no significant difference in the quality of responses between ChatGPT versions 3.5 and 4.0, suggesting that the improvements in AI technology do not compromise the model’s ability to deliver high-quality information. This consistency is crucial for integrating AI tools like ChatGPT into clinical practice, as it indicates reliability in providing accurate and comprehensive responses.
Conclusion
This study, conducted as a comparative analysis between AI-generated responses and those from medical professionals, offers valuable insights into the effectiveness of ChatGPT in laboratory medicine. While the study demonstrates ChatGPT’s potential to enhance patient education, it also acknowledges the limitations of AI, particularly in providing personalized care. The study is limited by its focus on responses from social media platforms and the subjective nature of the evaluation process. Nonetheless, the findings suggest that ChatGPT can be a powerful adjunct in healthcare, particularly in contexts where detailed, accurate information is paramount. Future research should explore integrating AI tools like ChatGPT into healthcare settings, ensuring they complement rather than replace the nuanced care provided by human professionals.

